Classification models + bet sizing for NFL games (feat. ChatGPT)
Plus, predictions for week 14 NFL games

Up to this point in Bayesball blogs, when it comes to supervised, parametric models, we’ve only investigated regression, which aims to predict continuous values like a score differential, batting average, or player efficiency. This week we’ll be taking on a few classification models, which work exactly how they sound - to classify observations with one (or in some cases multiple) of a defined list of labels. These models first compute the probability of an observation belonging to each of the defined labels and then, unless a different threshold for classification is set, assign the observation to whichever label had the highest predicted probability.
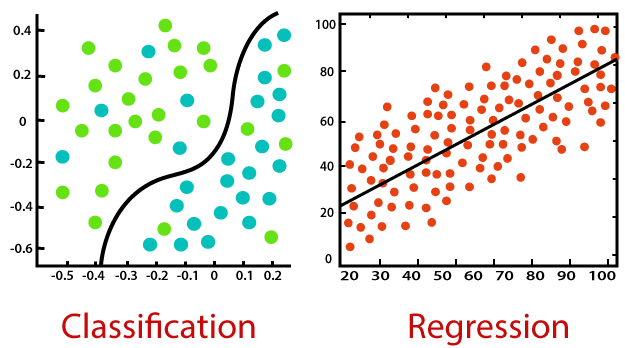
This week we’ll be moving on from the ElasticNet model used previously to predict point spreads, this time using that same training data to predict the probability of each team winning. We’ll then compare the model’s predictions on past games against the books’ predictions using historical spread lines to see how the model performs. Finally, we can then compare predicted probabilities for week 14 games against the probabilities implied by the money lines to craft an optimized betting portfolio using the Kelly criterion, explained later.
Classification models
For this section, I brought in an AI co-author, ChatGPT, to write some of the boring stuff for me. I’ll capture the OpenAI chatbot’s contributions in code blocks. If you just want to get to the application of each model and the model accuracy, feel free to skip to “model selection”.
Random Forest Classifier
Avid Bayesball readers will recognize that we’ve used Random Forest before, but as a regression model.
ChatGPT explanation, as Jar Jar Binks:
Meesa Jar Jar Binks. Meesa here to explain Random Forest Classification in American football terms.
Random Forest Classification is a way of making predictions about games of American football. It uses many different decision trees, which are like little branches in a forest, to make lots of different predictions. Then it combines all of these predictions together to make a final, more accurate prediction. This is a very clever way of making predictions and it can help us to know whether a team will win or lose a game.
Meesa hope meesa explanation make sense. Thank you for listening to meesa. Mee-sa out.
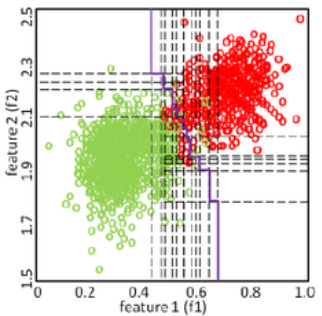
Logistic Regression
ChatGPT, but it hates public speaking:
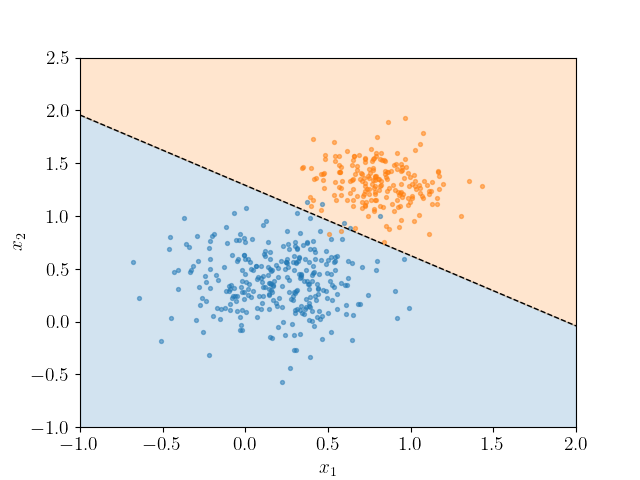
Log-log-logistic regression is a type of classification algorithm that is used to predict a b-binary outcome (i.e. a target variable that can take on only two v-values, such as "yes" or "no"). It works by finding a d-decision boundary that separates the data into two distinct classes, and it uses a mathematical f-function called the "logistic function" to map the input data to a probability between 0 and 1. This probability represents the likelihood that the outcome will be "yes" or "no". Logistic regression is a p-powerful and widely-used algorithm that is well-suited to many different types of classification tasks.
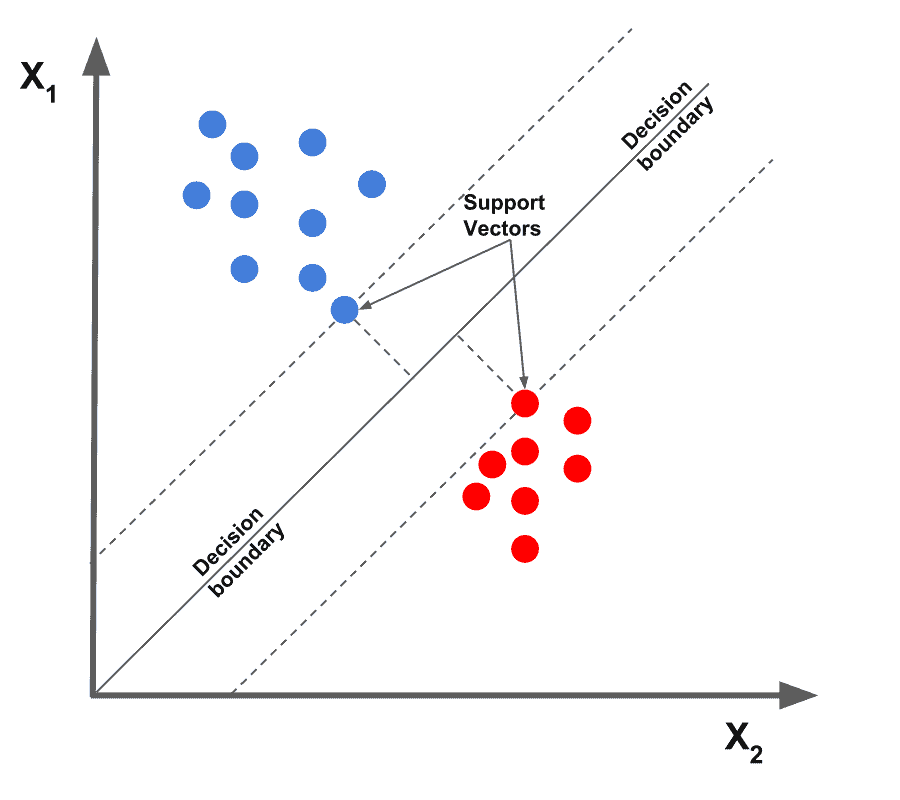
Support Vector Machine
Support Vector Machines (SVMs) are a type of supervised learning algorithm that can be used for classification and regression tasks. In sports betting, SVC could be used to predict the outcome of a game or a match based on historical data and statistical features of the teams or players involved. SVC works by finding a hyperplane (a decision boundary) that maximally separates the positive examples (winning games) from the negative examples (losing games) in the feature space. The hyperplane is chosen so that the distance between it and the nearest examples from each class (winning and losing games) is maximized, which helps to reduce the chances of misclassification.
K Nearest Neighbors
In American football, K-Nearest Neighbors (KNN) could be used to predict the outcome of a play based on the plays that have happened previously in the game. For example, if the current play is a third down with five yards to go, KNN could be used to classify the play as a pass or a run based on the plays that have happened in similar situations in the past. KNN would work by storing all the plays that have happened previously in the game, along with their outcomes (e.g. pass, run, incomplete, touchdown, etc.). When a new play occurs, KNN would calculate the similarity between the new play and the stored plays based on factors such as down, distance, field position, and game situation. It would then classify the new play based on the majority outcome among its K-nearest neighbors.
This is a good description, but in our case we’re just looking at the outcome of the game, not specific plays. The play-by-play approach could be a good idea for later though….
Model selection
Now that we’ve described the various leading classification models, let’s see how each performs on the 2010-2022 training set used previously (with weather, injury, and team performance data). Evaluating classification models is a bit different from evaluating regression models - we’re not looking at the mean absolute error anymore because there can’t be a numerical error between two labels. Instead, we can use a few different metrics - accuracy, precision, recall, and F1 are the most common, and accuracy is probably the most intuitive. Accuracy is simply 100 minus the error rate (the % of game outcomes that differed from the model’s predictions). When we look at how the four (hyperparameter-tuned) ML models performed (using 5 fold cross validation), we don’t see much of a difference between them. They all hover about 60% accuracy, with logistic regression leading the pack slightly, while KNN lags behind.
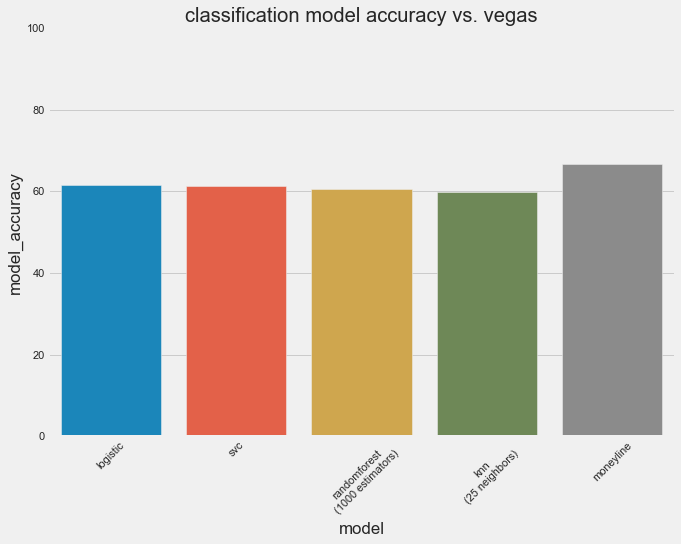
Historically, money lines have performed at about 66% accuracy. Another way of saying this is that from 2010-2022, two-thirds of the time the odds-on favorite has won the game. This is 5% better than our best model, which is a similar finding to that of the point-spread regression model. So, as a whole, Vegas still has an edge.
66% accuracy is still a bit lower than I’d think for the books, though. Here’s how the books’ have performed depending on how close the game was slated to be.
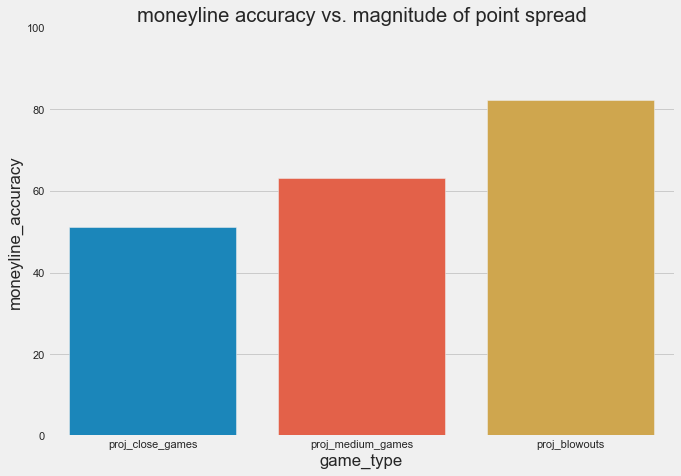
We take the absolute value of the spread for each game to classify games as “projected close” (absolute value of spread is 0-1.5, inclusive), “projected medium” (absolute value of spread between 1.5 and 7.5, exclusive), and “projected blowouts” (absolute value of spread greater than or equal to 7.5 points). As you’d expect, the heavy favorites win at a significantly higher rate (81%) than the slight favorites do (51%). When we treat the close games as a held-out test set, here’s how our models do:
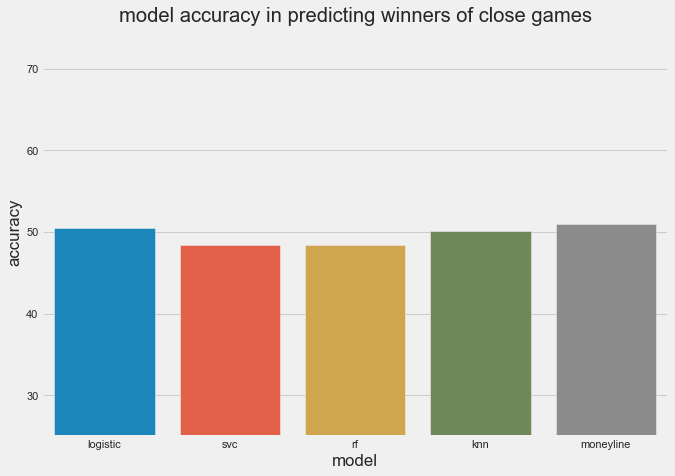
The money line still reigns supreme, but only by a half of a percentage point this time. Two of our models do slightly better than a coinflip in this small-ish sample (293 games).
Bet sizing
Now that we can use our model (the logistic regression, since it performed the best) to compute our probabilities of each team winning, we can use these probabilities in tandem with the offered betting lines to compute optimal bet sizes for each game. Now that’s sports betting like a hedge fund! The bet-sizing formula of choice is the Kelly criterion - which maximizes the expected bankroll growth rate for a bet given the calculated probability from our model and the known payout from the sportsbook-offered odds.
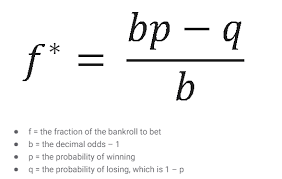
We can use this formula, plugging in the decimal odds (converted from American odds) from the sportsbooks as b, the probability of win from the model as p, and q as 1-p. Now, we can return picks, probability of win, and Kelly bet size (as a fraction of total bankroll) for each game!
Week 14 NFL predictions
Note - while the model may pick an underdog to win, the Kelly criterion will not place heavy bets on those underdogs, as they are expected to lose for a reason. In games where the model has the game a lot closer than the books do, look for the Kelly to suggest a small hedge on the underdog which minimizes downside risk in the event of a somewhat-likely upset. Also, for simplicity’s sake, I have rounded the bet sizes.
1:00 games
Buffalo Bills vs. New York Jets
Model prediction: Bills ML (52.36%), Kelly criterion: 12% of bankroll on Bills ML, 1% on Jets ML

I also like NYJ +10 because of how close the model has it and because the Jets beat the Bills last time.
Cincinnati Bengals vs. Cleveland Browns
Model prediction: Bengals ML (71.34%), Kelly criterion: 7% of bankroll on Bengals ML

The model doesn’t price in whether Deshaun Watson will get better after his so-so return to action last week. We can only hope he doesn’t.
Dallas Cowboys vs. Houston Texans
Model prediction: Cowboys ML (87.49%), Kelly criterion: 16% of bankroll on Cowboys ML

This is going to be an absolute embarrassment for the Texans. Covering at +18 would be a win for them but I’m not holding my breath on that one.
Detroit Lions vs. Minnesota Vikings
Model prediction: Lions ML (61.57%), Kelly criterion: 5% of bankroll on Lions ML

The lines for this game have been all over the place. I’ll take the surging Lions over the most fraudulent 11-2 team in recent history here. I also like Lions -2.5 as well, strictly based on how much the model loves the Lions here (top five in probability of win for this week).
New York Giants vs. Philadelphia Eagles
Model prediction: Eagles ML (75.89%), Kelly criterion: 8% of bankroll on Eagles ML

The points spread model suggests that Eagles -7 could be a prudent move here as well. Eagles will win handily.
Pittsburgh Steelers vs. Baltimore Ravens
Model prediction: Ravens ML (57.32%), Kelly criterion: 5% of bankroll on Steelers ML, 1% on Ravens ML

The model doesn’t capture everything. This is one of those instances where, even though the model projects the Ravens pulling this one off, it’s probably a better bet to go with the Steelers (with a small hedge for the Ravens).
Tennessee Titans vs. Jacksonville Jaguars
Model prediction: Jaguars ML (53.57%), Kelly criterion: 7% of bankroll on Titans ML, 1% on Jaguars ML

This will definitely be a close one, it could go either way. The Kelly wants us to put a slightly bigger bet on the favored Titans, but then also a small hedge as well, as with the last game.
4:00 games
Denver Broncos vs. Kansas City Chiefs
Model prediction: Chiefs ML (56.71%), Kelly criterion: 12% of bankroll on Chiefs ML, 1% on Broncos ML

Broncos are still on my no bet list so I’ll probably not hedge this one. If they weren’t on my no bet list, Broncos +8.5 would look pretty good, too.
Seattle Seahawks vs. Carolina Panthers
Model prediction: Panthers ML (50.06%), Kelly criterion: 7% of bankroll on Seahawks ML, 1% on Panthers ML

A literal coin flip! I’ll take the Kelly’s suggestion but then also Carolina +4.5 since this will be a close one
San Francisco 49ers vs. Tampa Bay Buccaneers
Model prediction: 49ers ML (56.39%), Kelly criterion: 6% of bankroll on 49ers ML

Will washed Tom Brady be outplayed by Mr. Irrelevant?
SNF
Los Angeles Chargers vs. Miami Dolphins
Model prediction: Dolphins ML (55.39%), Kelly criterion: 6% of bankroll on Dolphins ML

I can’t be the only one starting to hate this guy, right? He won’t get humbled this week but hopefully soon.
MNF
Arizona Cardinals vs. New England Patriots
Model prediction: Cardinals ML (52.67%), Kelly criterion: 6% of bankroll on Patriots ML, 1% of bankroll on Cardinals ML

Looking to be another great game, and this is this week’s only example of one of those “close games” where the favorite only wins 51% of the time. I like the Cardinals here but it could go either way.
Where can we get in touch? I'd like to discuss some NHL analytics